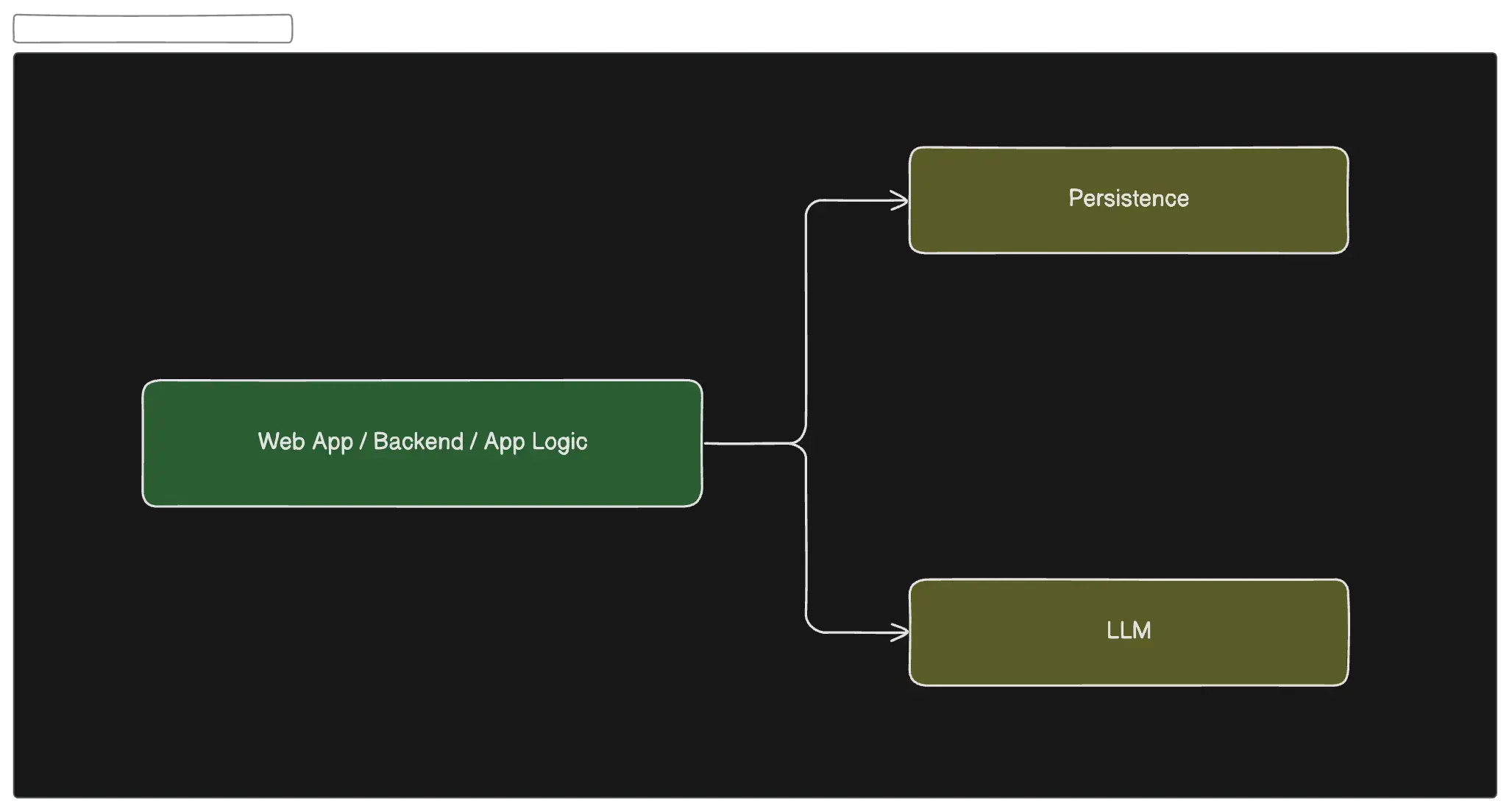
The landscape of Large Language Models (LLMs) is evolving rapidly, with powerful and open models being released at an unprecedented pace. As these technologies advance, so does the potential to integrate them into our existing systems. Traditionally, we’ve built systems with distinct layers such as the Application layer and Data Persistence layer.
In this post, I’ll guide you through the process of integrating LLMs into your systems. Having recently embarked on building my first LLM-native system, I’m excited to share some practical methods for incorporating these models into your workflows.
By the end of this video, you’ll have a clear understanding of how to:
- Identify suitable use cases for LLMs within your existing systems.
- Select the right LLM for your specific needs.
- Integrate LLMs with your current architecture seamlessly.
- Leverage the unique capabilities of LLMs to enhance your system’s functionality. Let’s dive in and explore the future of intelligent, language-driven systems together!
For the following post I will be using TMDB OpenAPI as a case study.
Integrating LLMs into System Architecture
Imagine having a powerful assistant embedded within your system, ready to tackle tasks on demand. That’s the potential of integrating Large Language Models (LLMs) into your systems. With LLMs, you can offload real-time jobs without needing to program each behavior explicitly.
Traditionally, system behaviors are hard-coded and tailored to specific business problems. However, LLMs offer an opportunity to build more versatile and adaptive systems. By combining the deterministic nature of traditional programming with the probabilistic power of LLMs, developers can create hybrid systems that:
- Adapt to new challenges.
- Generalize solutions across various problem sets.
- Leverage real-time language processing capabilities.
This approach doesn’t replace traditional programming but enhances it, enabling your systems to be more intelligent and flexible.
Data Cleanup and Enrichment
When building systems, we often start by importing existing datasets in formats like CSV or JSON. However, these datasets are rarely perfect and usually require cleanup and enrichment. Common issues include missing fields or data points that need enhancement.
Large Language Models (LLMs) can be invaluable in addressing these challenges. Here’s an example:
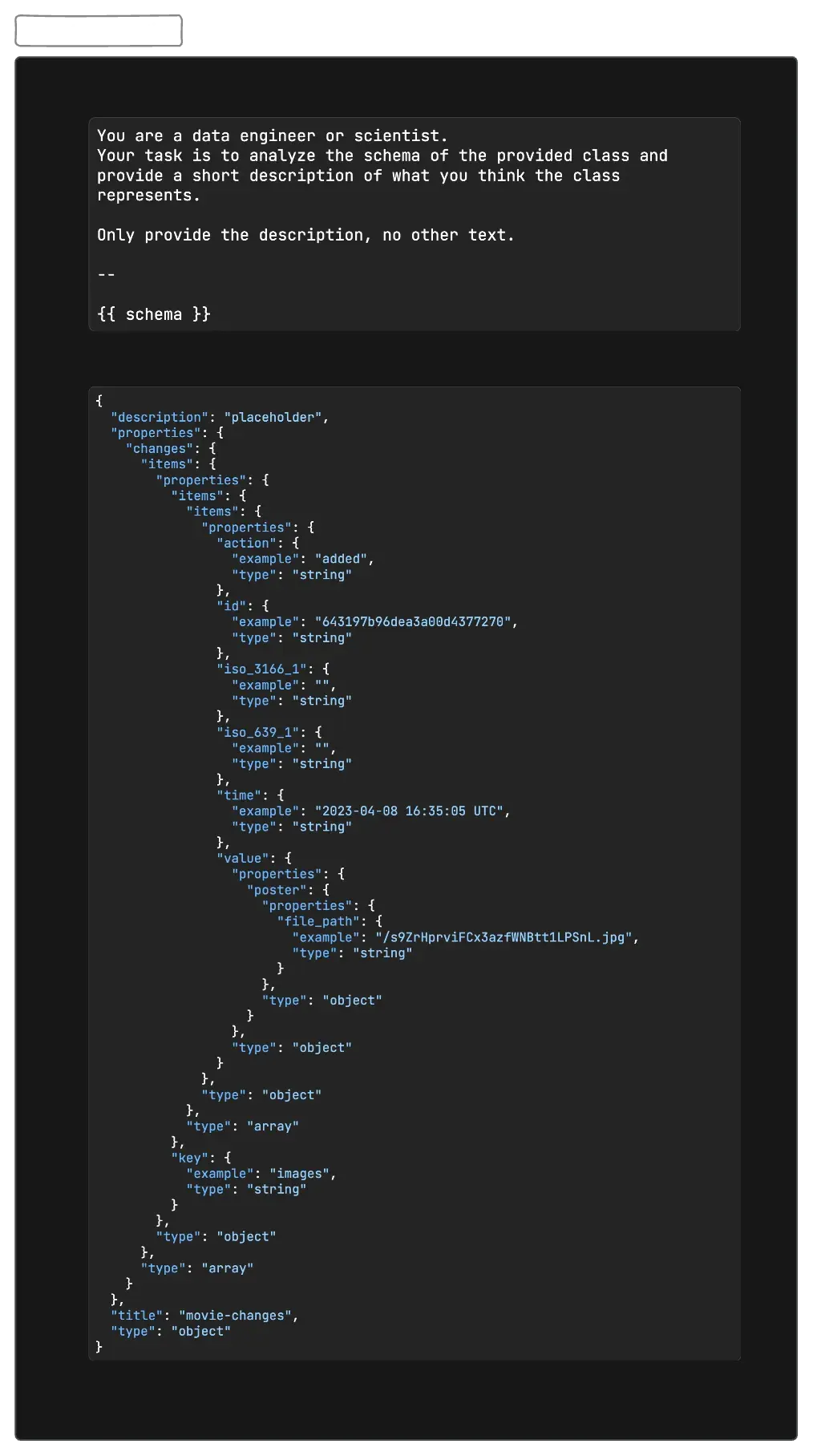
I recently imported a dataset that lacked ‘description’ fields for each entry. To remedy this, I fed the available data into an LLM and prompted it to generate descriptions based on the given information. The results were seamless and significantly enriched the dataset.
I had this schema:
{
"description": "placeholder",
"properties": {
"changes": {
"items": {
"properties": {
"items": {
"items": {
"properties": {
"action": {
"example": "added",
"type": "string"
},
"id": {
"example": "643197b96dea3a00d4377270",
"type": "string"
},
"iso_3166_1": {
"example": "",
"type": "string"
},
"iso_639_1": {
"example": "",
"type": "string"
},
"time": {
"example": "2023-04-08 16:35:05 UTC",
"type": "string"
},
"value": {
"properties": {
"poster": {
"properties": {
"file_path": {
"example": "/s9ZrHprviFCx3azfWNBtt1LPSnL.jpg",
"type": "string"
}
},
"type": "object"
}
},
"type": "object"
}
},
"type": "object"
},
"type": "array"
},
"key": {
"example": "images",
"type": "string"
}
},
"type": "object"
},
"type": "array"
}
},
"title": "movie-changes",
"type": "object"
}The schema provided lacked a clear description, even though its structure was familiar. To address this, I leveraged a Large Language Model (LLM) to generate a descriptive summary. Here’s the result:
A record of changes made to movie metadata, specifically related to images, including actions (added), timestamps, and details about the image files (like file paths).
I ran this on 100s of records. The results are impressive. In the past, generating such descriptions would have required significant time and resources, potentially involving hiring someone to write them manually. Now, with the help of my ”👻 writer” (LLM), I can obtain high-quality descriptions efficiently.
Here is the prompt I used:
You are a data engineer or scientist.
Your task is to analyze the schema of the provided class and provide a short description of what you think the class represents.
Only provide the description, no other text.
--
{{ schema }}It’s not always perfect but I would say even if it gets it right 90% - 95% of the time that’s already significant. Remember we had nothing before.
Prompt Templating
To integrate LLMs into my system, I store prompts either in the database or directly in the code, depending on the specific use case. These prompts are designed as Liquid templates, allowing for dynamic content generation. Here’s how it works:
- Template Storage: Prompts are saved as Liquid templates in either the database or the codebase.
- Data Injection: Relevant data from the database is injected into these templates.
- Prompt Generation: The final prompt is generated by merging the template with the provided data.
- LLM Integration: This complete prompt is then passed to the LLM for processing.
This approach ensures flexibility and reusability, enabling efficient interaction with LLMs tailored to various scenarios.
Here is an elixir example using the :solid library to render prompts dynamically.
@prompt
|> Solid.parse!()
|> Solid.render!(%{"schema" => schema})
|> to_string()Generalized Problem Solving
Consider a scenario where you have a list of paths that need to be grouped. This is another excellent use case for leveraging the power of LLMs.
/3/collection/{collection_id}/translations
/3/network/{network_id}/alternative_names
/3/tv/season/{season_id}/changes
/3/certification/tv/list
/3/movie/{movie_id}/keywords
/3/configuration/countries
/3/movie/{movie_id}/watch/providers
/3/tv/{series_id}/season/{season_number}/external_ids
/3/account/{account_id}/lists
/3/company/{company_id}/images
/3/tv/{series_id}/season/{season_number}/episode/{episode_number}/images
/3/tv/{series_id}/screened_theatrically
/3/search/tv
/3/person/{person_id}/tagged_images
/3/tv/{series_id}/alternative_titles
/3/tv/{series_id}/reviews
/3/find/{external_id}
/3/account/{account_id}/rated/tv
/3/movie/{movie_id}/external_ids
/3/tv/{series_id}/season/{season_number}/episode/{episode_number}
/3/search/keyword
/3/watch/providers/tv
/3/network/{network_id}/images
/3/tv/on_the_air
/3/certification/movie/list
/3/tv/{series_id}/aggregate_credits
/3/person/changes
/3/tv/{series_id}/images
/3/account/{account_id}/rated/tv/episodes
/3/account/{account_id}
/3/movie/{movie_id}/alternative_titles
/3/movie/{movie_id}/similar
/3/tv/{series_id}/season/{season_number}/credits
/3/guest_session/{guest_session_id}/rated/tv
/3/search/company
/3/account/{account_id}/watchlist/movies
/3/search/person
/3/person/{person_id}/combined_credits
/3/movie/{movie_id}
/3/movie/{movie_id}/changes
/3/keyword/{keyword_id}/movies
/3/tv/{series_id}/credits
/3/review/{review_id}
/3/guest_session/{guest_session_id}/rated/movies
/3/person/{person_id}/tv_credits
/3/tv/{series_id}/episode_groups
/3/person/{person_id}/external_ids
/3/search/collection
/3/tv/airing_today
/3/collection/{collection_id}
/3/tv/{series_id}/keywords
/3/tv/latest
/3/movie/{movie_id}/translations
/3/person/{person_id}/changes
/3/tv/{series_id}/season/{season_number}/episode/{episode_number}/credits
/3/movie/latest
/3/company/{company_id}
/3/person/latest
/3/movie/{movie_id}/reviews
/3/list/{list_id}
/3/movie/{movie_id}/release_dates
/3/movie/{movie_id}/videos
/3/account/{account_id}/watchlist/tv
/3/tv/{series_id}/season/{season_number}/watch/providers
/3/tv/{series_id}/season/{season_number}/aggregate_credits
/3/watch/providers/movie
/3/tv/{series_id}/lists
/3/trending/person/{time_window}
/3/tv/{series_id}/season/{season_number}/translations
/3/person/popular
/3/search/multi
/3/movie/upcoming
/3/tv/{series_id}
/3/tv/{series_id}/season/{season_number}/episode/{episode_number}/external_ids
/3/list/{list_id}/item_status
/3/tv/changes
/3/tv/{series_id}/watch/providers
/3/authentication
/3/configuration/jobs
/3/tv/{series_id}/season/{season_number}/episode/{episode_number}/account_states
/3/movie/{movie_id}/account_states
/3/credit/{credit_id}
/3/watch/providers/regions
/3/tv/{series_id}/changes
/3/trending/tv/{time_window}
/3/configuration/timezones
/3/configuration/primary_translations
/3/person/{person_id}
/3/tv/{series_id}/videos
/3/movie/top_rated
/3/person/{person_id}/movie_credits
/3/guest_session/{guest_session_id}/rated/tv/episodes
/3/tv/{series_id}/content_ratings
/3/account/{account_id}/favorite/tv
/3/discover/movie
/3/tv/top_rated
/3/trending/movie/{time_window}
/3/person/{person_id}/images
/3/tv/popular
/3/trending/all/{time_window}
/3/movie/{movie_id}/recommendations
/3/collection/{collection_id}/images
/3/movie/{movie_id}/lists
/3/authentication/token/new
/3/tv/{series_id}/recommendations
/3/tv/{series_id}/season/{season_number}/videos
/3/tv/{series_id}/season/{season_number}/episode/{episode_number}/videos
/3/account/{account_id}/rated/movies
/3/movie/now_playing
/3/tv/{series_id}/external_ids
/3/configuration/languages
/3/movie/{movie_id}/images
/3/tv/{series_id}/season/{season_number}/account_states
/3/tv/{series_id}/season/{season_number}/episode/{episode_number}/translations
/3/tv/{series_id}/translations
/3/movie/popular
/3/keyword/{keyword_id}
/3/tv/{series_id}/season/{season_number}/images
/3/tv/episode/{episode_id}/changes
/3/tv/{series_id}/season/{season_number}
/3/discover/tv
/3/search/movie
/3/person/{person_id}/translations
/3/genre/movie/list
/3/network/{network_id}
/3/genre/tv/list
/3/tv/{series_id}/similar
/3/configuration
/3/movie/changes
/3/account/{account_id}/favorite/movies
/3/tv/episode_group/{tv_episode_group_id}
/3/authentication/guest_session/new
/3/company/{company_id}/alternative_names
/3/tv/{series_id}/account_states
/3/movie/{movie_id}/creditsOne approach to detect the resource name in a path is by using regular expressions (regex). For instance, you might identify that the second section of the path represents the group:
/3/movie/{movie_id}/keywords -> movie groupHowever, regex can fall short when encountering varied or unexpected path patterns. For example:
/api/internal/movie/{movie_id}/keywordsIn such cases, another effective approach is to leverage an LLM to handle the grouping task. LLMs can better adapt to diverse and complex path structures.
Group the following paths into a list of classes, based on the entity in the path.
The classes should be named in a way that is URL friendly.
Be careful not to mix entities of different classes in the same group.
--
{{paths}}It’s crucial to recognize that when integrating LLMs, you are trading determinism for generalization. However, it is possible to design systems that effectively handle non-determinism. As we increasingly incorporate LLMs into our workflows, I anticipate that new design patterns will emerge to address these challenges.
To ensure the results are useful and actionable, I used structured output formats. This approach allows me to store the LLM-generated data in my database for use in subsequent operations. Here is an example of the structured output I obtained:
[
{
"description": "Paths related to movies.",
"name": "movie",
"paths": [
"/3/movie/{movie_id}/credits",
"/3/movie/top_rated",
"/3/movie/{movie_id}/account_states",
"/3/movie/changes",
"/3/movie/popular",
"/3/genre/movie/list",
"/3/movie/{movie_id}/images",
"/3/trending/movie/{time_window}",
"/3/movie/{movie_id}/lists",
"/3/movie/now_playing",
"/3/movie/{movie_id}/recommendations",
"/3/movie/{movie_id}/videos",
"/3/movie/{movie_id}/release_dates",
"/3/movie/upcoming",
"/3/movie/{movie_id}/translations",
"/3/movie/{movie_id}/changes",
"/3/movie/latest",
"/3/movie/{movie_id}/similar",
"/3/movie/{movie_id}/alternative_titles",
"/3/movie/{movie_id}/external_ids",
"/3/movie/{movie_id}/watch/providers",
"/3/movie/{movie_id}/reviews",
"/3/movie/{movie_id}/keywords",
"/3/movie/{movie_id}"
]
}
// ...redacted for brevity
]The results are impressive! I’ve experimented with multiple models— **qwen2.5**, **gemma3**, and **mistral-small** —and found that they all perform well. Ultimately, I chose to go with Gemma 3 12b for my needs.
I’ll be creating a follow-up content comparing the outputs of these models in more detail. Make sure to subscribe to my channel so you won’t miss it!
Systems that can Adapt and Grow
Envision this scenario: You’re developing a system capable of accessing any API by simply providing it with specifications. The system should then be able to infer independently how to call the API based on those specs.
Let’s consider a practical case using data from an OpenAPI specification:
{
"in": "path",
"name": "movie_id",
"required": true,
"schema": {
"format": "int32",
"type": "integer"
}
}and you had this schema:
{
"description": "A movie and its associated cast and crew information.",
"properties": {
"cast": {
//...redacted for brevity
},
"crew": {
//...redacted for brevity
},
"id": {
"default": 0,
"example": 550,
"type": "integer"
}
},
"title": "movie-credits",
"type": "object"
}A developer examining this data structure would be able to manually create a client that uses the **id** as the **movie_id**. Alternatively, one could use a code generator to automate the creation of this client. However, LLMs offer an even more straightforward solution.
By simply prompting the LLM with the relevant information, it can generate the appropriate client code for you. For example, you might ask:
Which of the property in this schema is likely to map to the parameter.
Schema:
{{ schema }}
Parameter:
{{ parameter }}Asking Gemma3 12b with structured output:
{
"type": "object",
"title": "mapping",
"description": "Mapping from schema to parameter",
"properties": {
"field": {
"type": "string",
"description": "The property in the schema."
},
"maps_to": {
"type": "string",
"description": "Parameter name"
}
},
"required": ["field", "maps_to"],
"additionalProperties": false
}I got the following with zero-shot:
{
"field": "id",
"maps_to": "movie_id"
}We can now use this output to dynamically make requests by retrieving the id from the data and pass it as the movie_id in our request.
Working with Non-Determinism
You might attribute my success to luck, but I believe there’s a way to transform that luck into consistent reality.
Beyond testing and iterating on your prompts, you can design systems that anticipate and manage non-deterministic outputs from LLMs. We already have experience building fault-tolerant systems, so extending this mindset to handle the variability of LLM responses is a natural next step.
By incorporating strategies such as:
- Output validation
- Fallback mechanisms
- Confidence thresholding
we can create robust systems that leverage the power of LLMs while accounting for their inherent non-determinism.
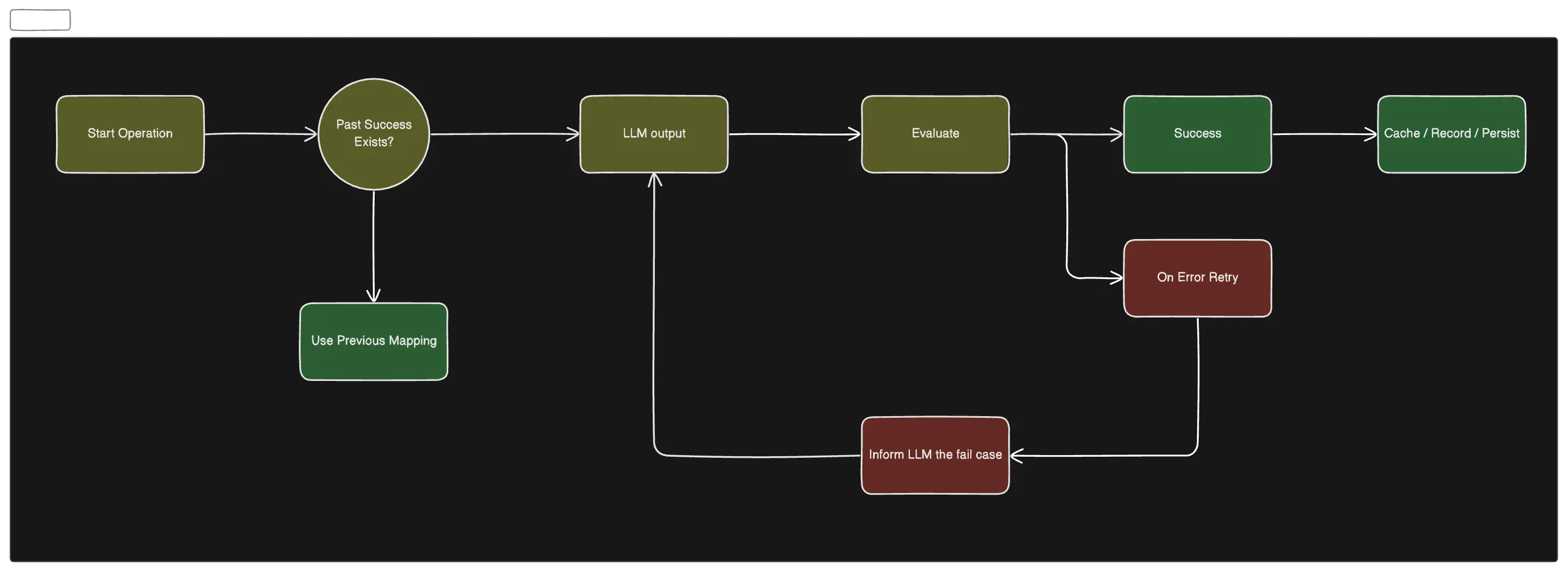
Operation Initiation
To begin, you kick off the operation by first checking if there has been a previous case where the given endpoint was called with the specified parameters. If not, you leverage the LLM to map the fields and make the API call.
Evaluation Loop
If the initial call fails, implement a retry mechanism that records the failed scenario. To enhance adaptability, consider using a prompt that evolves based on the number of retries and previous attempts, providing the LLM with contextual information.
On successful execution, persist the result in your database. This approach ensures that the output can be reused for subsequent calls, eliminating the need to consult the LLM again for the same API, as APIs typically do not change frequently.
In the worst-case scenario, if the LLM fails to produce any usable output, implement a stop condition to prevent infinite retries. In such cases, human intervention may be required to resolve the issue.
Stigmergy: Inspiring Adaptive Systems
In nature, stigmergy is a concept where the trace left in the environment by an individual action stimulates subsequent actions by the same or different agents. This principle can be effectively applied to building adaptive systems using LLMs and AI models.
Rather than defining explicit behaviors, we can harness LLMs to create systems that evolve through data-driven traces left in their environment. This approach brings us closer to developing more generalized, adaptable systems that grow organically.
To achieve this, we:
- Establish basic constraints and rules to enable the subsystem’s initial operation.
- Leave sufficient environmental traces for the system to infer its next steps autonomously.
- Leverage LLMs to fill gaps or resolve ambiguities, guiding the system through small, incremental progressions.
These incremental steps, though small individually, can number in the thousands within a given system. The potential of such a stigmergic system, when fully realized, is both fascinating and promising. It represents a new paradigm in system building – one that embraces the generative nature of LLMs to create reliable, organic digital systems.
By adopting this approach, we shift from prescribing every detail to fostering adaptive growth, allowing our systems to evolve and improve continually.